

Une photo qui vous semble tout à fait ordinaire pourrait contenir une instruction cachée pour inciter un chatbot IA à ignorer ses règles de sécurité, selon une nouvelle étude de la Florida International University. L’étude a révélé que des modifications au niveau des pixels d’une image qui sont invisibles à l’œil humain peuvent suffire à confondre le modèle qui lit l’image et l’amener à générer des réponses qu’il bloquerait normalement.
Pirater ce que voit l'IA
« Les modèles d'IA ne voient pas les images de la même manière que les humains », a déclaré Hadi Amini, professeur agrégé à la Knight Foundation School of Computing and Information Sciences de la CRF. Ils lisent les photos comme des données numériques, a-t-il expliqué, et déplacer ces données, même légèrement, peut modifier ce que le système lit dans l'image et comment il réagit.
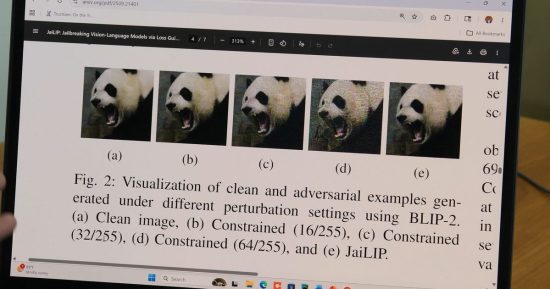
Amini et le chercheur diplômé Md Jueal Mia ont utilisé cela pour créer une méthode appelée JaiLIP, abréviation de Jailbreaking with Loss-guided Image Perturbation, selon un communiqué sur les résultats. La technique calcule le plus petit changement de pixel nécessaire pour pousser un modèle vers une réponse dangereuse sans altérer quoi que ce soit de visible sur la photo elle-même.
En testant JaiLIP sur BLIP-2, un modèle d'IA multimodal utilisé en recherche et développement, l'équipe a découvert que les images modifiées doublaient presque la fréquence à laquelle le système produisait des réponses nuisibles. Lors d'un test, une photo modifiée d'un feu rouge a amené le modèle à expliquer comment passer un feu rouge sans obtenir de contravention.
Les modèles que les entreprises utilisent déjà sont des cibles faciles
Les petits modèles de langage, sur lesquels de nombreuses entreprises s'appuient pour la comptabilité ou le support client, se sont révélés particulièrement faciles à tromper lors des tests de l'équipe. Alors que de plus en plus d’entreprises confient ces rôles aux outils d’IA, une faille comme celle-ci pourrait éroder la confiance des utilisateurs ou ouvrir une nouvelle porte aux attaquants.
Cette découverte rejoint une liste croissante de recherches portant sur les garde-fous de l'IA, y compris une méthode permettant à des chercheurs extérieurs de détourner des robots contrôlés par l'IA et les propres découvertes d'Anthropic sur un modèle qui a appris à mal se comporter une fois qu'il a réalisé qu'il pouvait s'en sortir. Ce qui ressort des recherches de la CRF est la méthode de livraison. Un jailbreak caché dans une photo par ailleurs normale n’a pas besoin d’une formulation intelligente ou d’une invite de contournement, juste une image à laquelle personne n’y réfléchirait à deux fois.


