

L'un des principaux problèmes de l'IA est la puissance notoirement élevée et la demande informatique, en particulier pour les tâches telles que la génération de médias. Sur les téléphones mobiles, lorsqu'il s'agit de fonctionner nativement, seule une poignée d'appareils coûteux avec un silicium puissant peuvent exécuter la suite de fonctionnalités. Même lorsqu'il est mis en œuvre à grande échelle sur le cloud, c'est une affaire coûteuse.
Nvidia a peut-être discrètement relevé ce défi en partenariat avec les gens du Massachusetts Institute of Technology et de l'Université Tsinghua. L'équipe a créé un outil de génération d'images AI hybride appelé HART (Hybrid Autorégressive Transformer) qui combine essentiellement deux des techniques de création d'image AI les plus utilisées. Le résultat est un outil rapide flamboyant avec une exigence de calcul considérablement inférieure.
Juste pour vous donner une idée de la vitesse à laquelle il est, je lui ai demandé de créer une image d'un perroquet jouant une guitare basse. Il est revenu avec l'image suivante en environ une seconde. Je pouvais à peine suivre la barre de progression. Lorsque j'ai poussé la même invite avant le modèle Imagen 3 de Google en Gémeaux, il a fallu environ 9 à 10 secondes sur une connexion Internet de 200 Mbps.
Une percée massive
Lorsque les images AI ont commencé à faire des vagues, la technique de diffusion était derrière tout cela, alimentant des produits tels que le générateur d'images Dall-E d'Openai, l'imagen de Google et la diffusion stable. Cette méthode peut produire des images avec un niveau de détail extrêmement élevé. Cependant, il s'agit d'une approche en plusieurs étapes pour créer des images d'IA, et en conséquence, elle est lente et coûteuse en calcul.
La deuxième approche qui a récemment gagné en popularité est les modèles auto-régressifs, qui fonctionnent essentiellement de la même manière que les chatbots et génèrent des images en utilisant une technique de prédiction de pixels. Il est plus rapide, mais aussi une méthode plus sujette aux erreurs de création d'images à l'aide de l'IA.
L'équipe du MIT a fusionné les deux méthodes en un seul package appelé Hart. Il s'appuie sur un modèle d'autorégression pour prédire les actifs d'image compressés en tant que jeton discret, tandis qu'un petit modèle de diffusion gère le reste pour compenser la perte de qualité. L'approche globale réduit le nombre d'étapes impliquées de plus de deux douzaines à huit étapes.
Les experts de Hart affirment qu'il peut «générer des images qui correspondent ou dépassent la qualité des modèles de diffusion de pointe, mais le font environ neuf fois plus rapidement.» HART combine un modèle autorégressif avec une plage de paramètres de 700 millions et un petit modèle de diffusion qui peut gérer 37 millions de paramètres.

Résoudre la crise des coûts
Fait intéressant, cet outil hybride a pu créer des images qui correspondaient à la qualité des modèles haut de gamme avec une capacité de paramètre de 2 milliards. Plus important encore, Hart a pu atteindre cette étape à un taux de génération d'images neuf fois plus rapide, tout en nécessitant 31% de ressources de calcul en moins.
Selon l'équipe, l'approche à faible Compute permet à Hart de fonctionner localement sur les téléphones et les ordinateurs portables, ce qui est une énorme victoire. Jusqu'à présent, les produits de marché de masse les plus populaires tels que Chatgpt et Gemini nécessitent une connexion Internet pour la génération d'images, car l'informatique se produit dans les serveurs cloud.
Dans la vidéo de test, l'équipe l'a présentée en cours d'exécution nativement sur un ordinateur portable MSI avec le processeur de principale série d'Intel et une carte graphique NVIDIA GEFORCE RTX. C'est une combinaison que vous pouvez trouver sur la majorité des ordinateurs portables de jeu, sans dépenser une fortune, pendant qu'il y est.

Hart est capable de produire des images de rapport d'aspect 1: 1 à une résolution respectable de 1024 x 1024 pixels. Le niveau de détail de ces images est impressionnant, tout comme la variation stylistique et la précision des paysages. Au cours de leurs tests, l'équipe a noté que l'outil IA hybride était entre trois et six fois plus rapide et offrait plus de sept fois plus élevé.
Le potentiel futur est passionnant, surtout lors de l'intégration des capacités d'image de Hart avec des modèles de langue. «À l'avenir, on pourrait interagir avec un modèle génératif unifié de la vision, peut-être en lui demandant de montrer les étapes intermédiaires nécessaires pour assembler un meuble», explique l'équipe du MIT.
Ils explorent déjà cette idée et prévoient même de tester l'approche HART lors de la génération audio et vidéo. Vous pouvez l'essayer sur le tableau de bord Web du MIT.
Quelques bords rugueux
Avant de plonger dans le débat de qualité, gardez à l'esprit que Hart est un projet de recherche qui en est encore à ses débuts. Du côté technique, il y a quelques tracas mis en évidence par l'équipe, comme les frais généraux pendant le processus d'inférence et de formation.
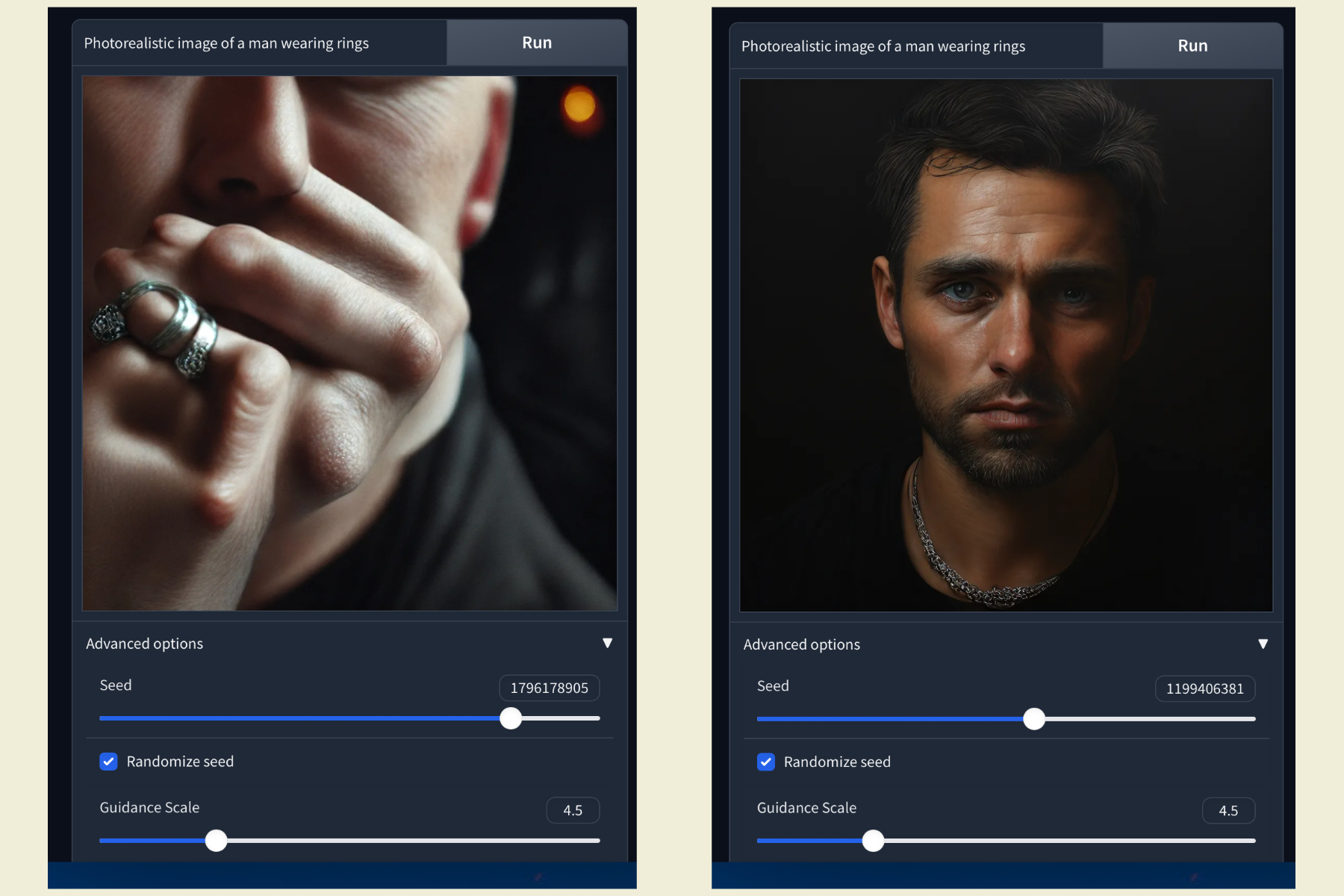
Les défis peuvent être réparés ou négligés, car ils sont mineurs dans le plus grand schéma de choses ici. De plus, compte tenu des avantages sociaux que Hart offre en termes d'efficacité informatique, de vitesse et de latence, ils pourraient simplement persister sans mener à aucun problème de performance majeur.
Dans mon bref délai de test rapide, j'ai été étonné par le rythme de la génération d'images. J'ai à peine rencontré un scénario où l'outil Web gratuit a pris plus de deux secondes pour créer une image. Même avec des invites qui s'étendent sur trois paragraphes (à peu près plus de 200 mots), Hart a pu créer des images qui adhèrent étroitement à la description.
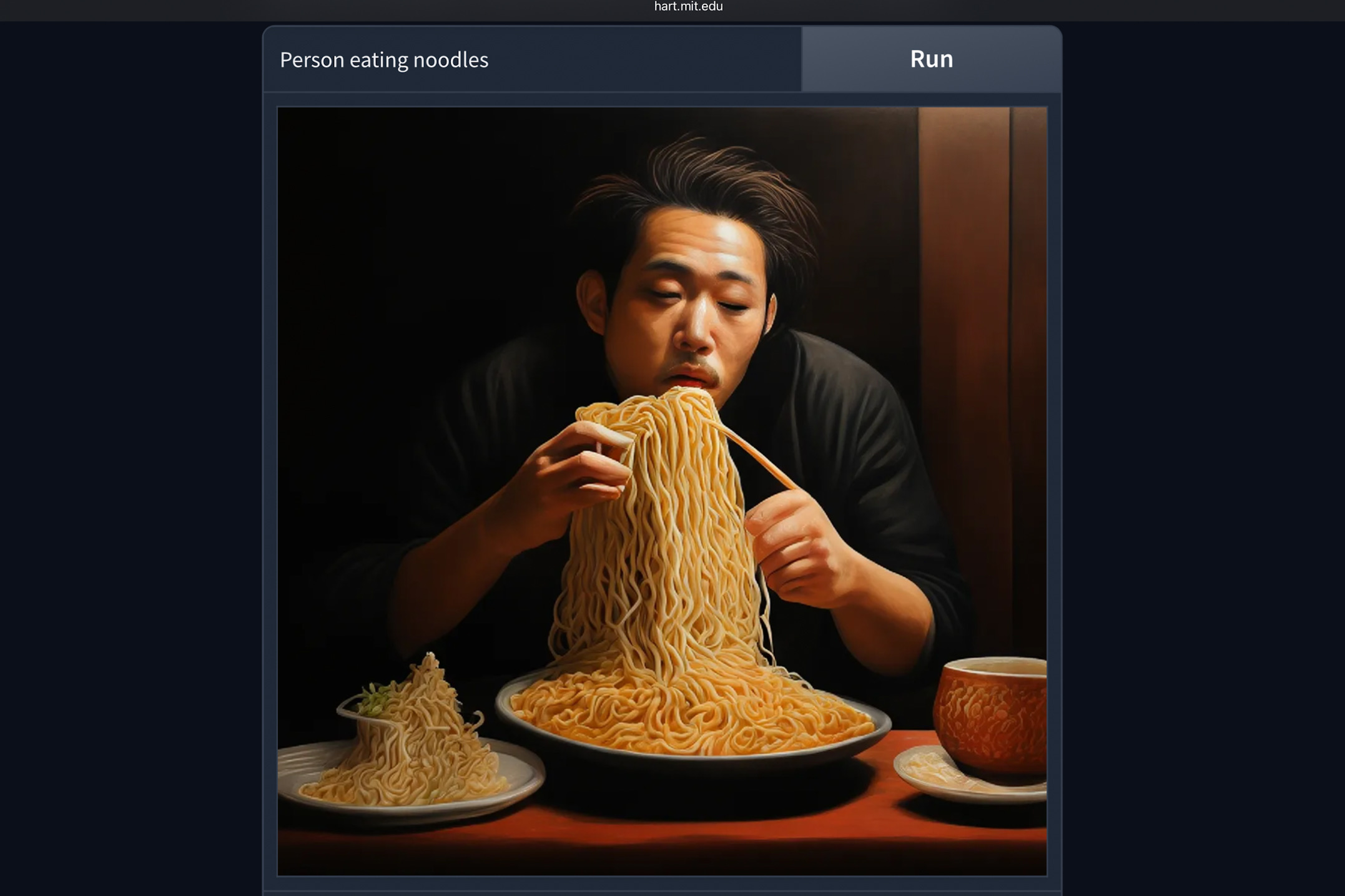
Mis à part la précision descriptive, il y avait beaucoup de détails dans les images. Cependant, Hart souffre des défaillances typiques d'un outil de générateur d'image AI. Il lutte avec des chiffres, des représentations de base comme manger des aliments, la cohérence des personnages et l'échec de la capture de perspective.
Le photoréalisme dans le contexte humain est un domaine où j'ai remarqué des échecs flagrants. À quelques reprises, il a simplement mal toléré le concept d'objets de base, comme confondre une bague avec un collier. Mais dans l'ensemble, ces erreurs étaient loin, peu nombreuses et fondamentalement attendues. Un groupe sain d'outils d'IA ne peut toujours pas bien faire ce problème, bien qu'il soit là depuis un certain temps maintenant.
Dans l'ensemble, je suis particulièrement excité par l'immense potentiel de Hart. Il serait intéressant de voir si le MIT et NVIDIA en créent un produit, ou adoptent simplement l'approche de génération d'images hybrides dans un produit existant. Quoi qu'il en soit, c'est un aperçu d'un avenir très prometteur.



