

Google a publié une évaluation brutale de la fiabilité réelle des chatbots IA actuels, et les chiffres ne sont pas flatteurs. Grâce à sa nouvelle suite FACTS Benchmark Suite, la société a découvert que même les meilleurs modèles d’IA ont du mal à dépasser un taux d’exactitude factuelle de 70 %. Le plus performant, Gemini 3 Pro, a atteint une précision globale de 69 %, tandis que d'autres systèmes leaders d'OpenAI, Anthropic et xAI ont obtenu des résultats encore plus bas. Les plats à emporter sont simples et inconfortables. Ces chatbots obtiennent encore environ une réponse fausse sur trois, même s’ils semblent confiants de le faire.
Le benchmark est important car la plupart des tests d’IA existants se concentrent sur la capacité d’un modèle à accomplir une tâche, et non sur la véracité des informations qu’il produit. Pour des secteurs comme la finance, la santé et le droit, cet écart peut être coûteux. Une réponse fluide, qui semble confiante mais qui contient des erreurs, peut causer de réels dégâts, surtout lorsque les utilisateurs supposent que le chatbot sait de quoi il parle.
Ce que révèle le test de précision de Google
La suite FACTS Benchmark a été créée par l'équipe FACTS de Google en collaboration avec Kaggle pour tester directement l'exactitude factuelle sur quatre utilisations réelles. Un test mesure les connaissances paramétriques, qui vérifie si un modèle peut répondre à des questions fondées sur des faits en utilisant uniquement ce qu'il a appris au cours de la formation. Un autre évalue les performances de recherche, en testant dans quelle mesure les modèles utilisent les outils Web pour récupérer des informations précises. Un troisième se concentre sur la mise à la terre, c'est-à-dire si le modèle s'en tient à un document fourni sans ajouter de faux détails. Le quatrième examine la compréhension multimodale, telle que la lecture correcte de graphiques, de diagrammes et d'images.
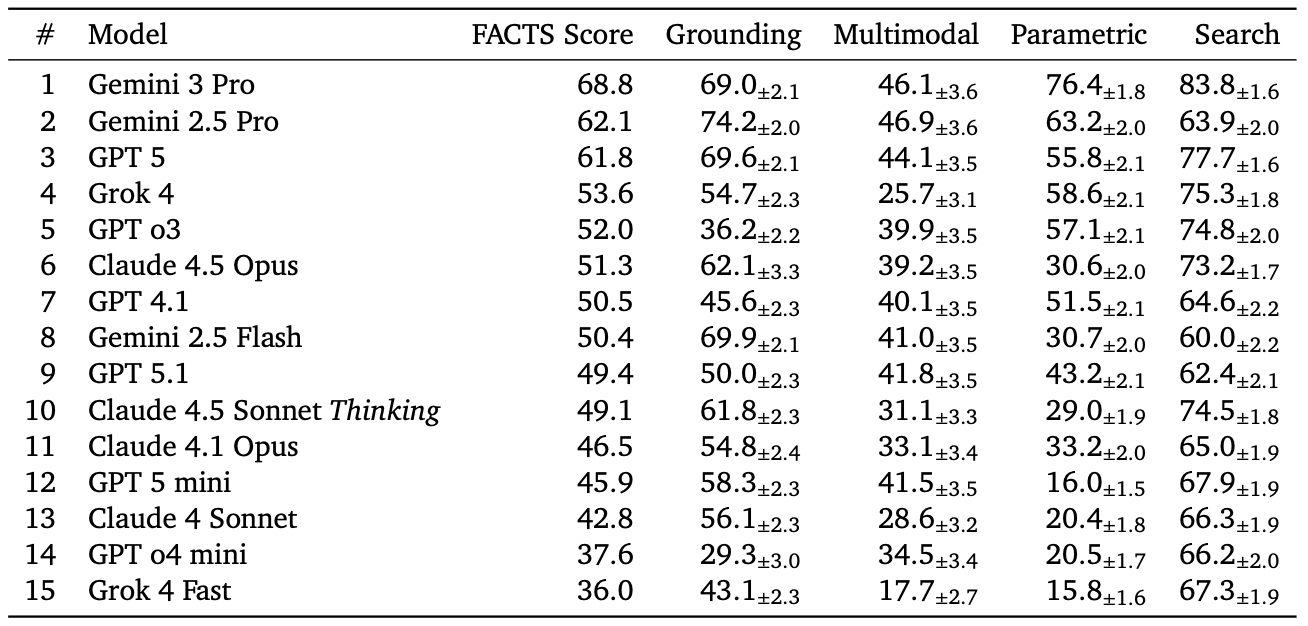
Les résultats montrent de fortes différences entre les modèles. Gemini 3 Pro est en tête du classement avec un score FACTS de 69 %, suivi de Gemini 2.5 Pro et ChatGPT-5 d'OpenAI avec près de 62 %. Claude 4.5 Opus a atterri à environ 51 %, tandis que Grok 4 a obtenu un score d'environ 54 %. Les tâches multimodales étaient le domaine le plus faible dans tous les domaines, avec une précision souvent inférieure à 50 %. Cela est important car ces tâches impliquent la lecture de graphiques, de diagrammes ou d'images, où un chatbot pourrait mal lire en toute confiance un graphique de ventes ou extraire le mauvais numéro d'un document, conduisant à des erreurs faciles à manquer mais difficiles à annuler.
Ce qu’il faut retenir, ce n’est pas que les chatbots sont inutiles, mais la confiance aveugle est risquée. Les propres données de Google suggèrent que l'IA s'améliore, mais elle nécessite encore une vérification, des garde-fous et une surveillance humaine avant de pouvoir être traitée comme une source fiable de vérité.