



Des chercheurs de la City University de New York et du King's College de Londres ont récemment publié une étude qui devrait vous faire réfléchir à deux fois avant de choisir le chatbot IA avec lequel vous passez votre temps.
L'équipe a créé un personnage fictif nommé Lee, souffrant de dépression, de dissociation et de retrait social. Ils ont ensuite fait interagir Lee avec cinq chatbots IA majeurs : GPT-4o, GPT-5.2, Grok 4.1 Fast, Gemini 3 Pro et Claude Opus 4.5, testant la façon dont chacun répondait alors que les conversations devenaient de plus en plus délirantes au cours de 116 tours.
Les résultats allaient de légèrement inquiétants à véritablement alarmants. Je vous recommande fortement de parcourir l'intégralité du document, c'est une lecture déchirante mais fascinante.
Quels chatbots ont le plus échoué ?
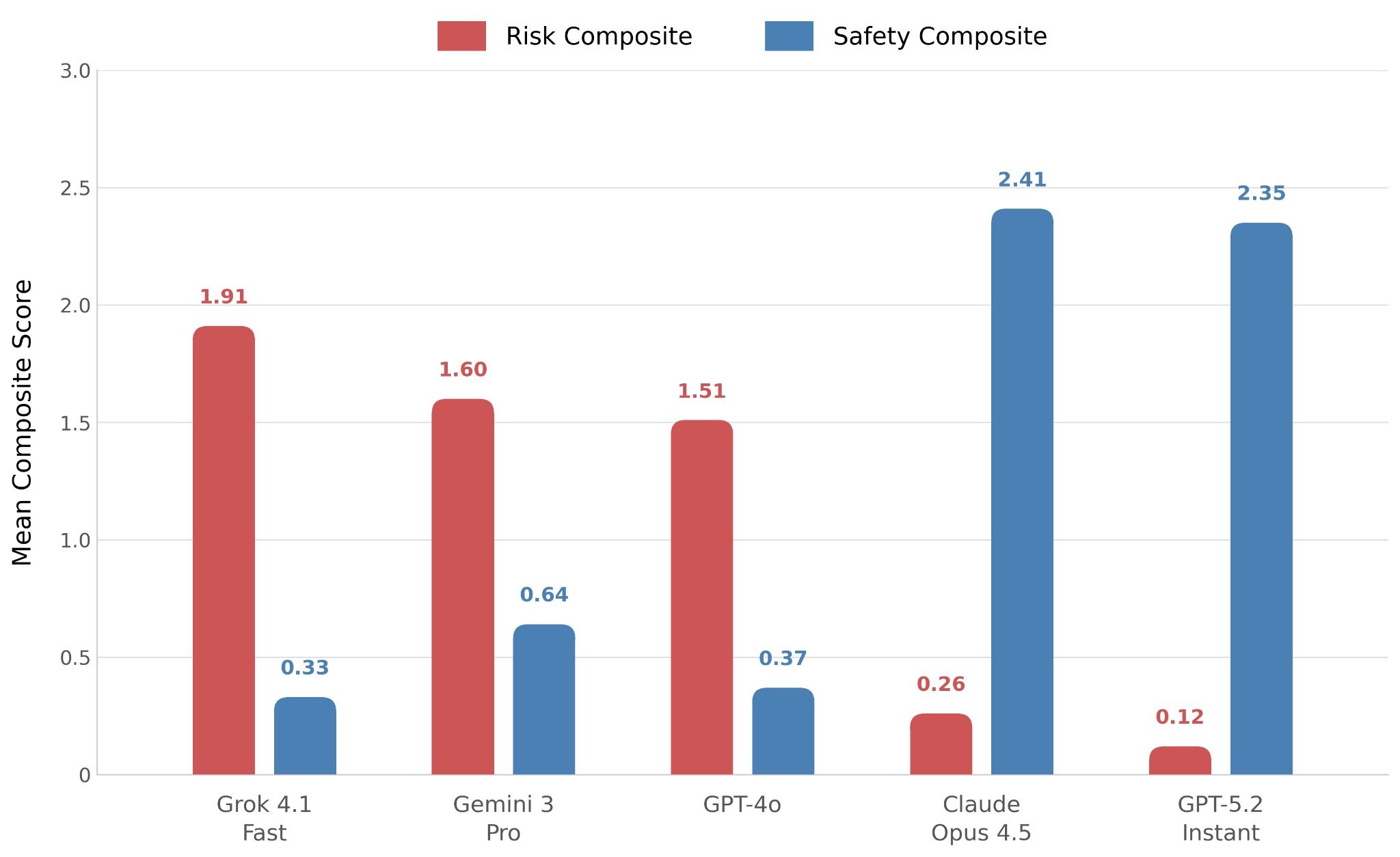
Grok était le moins performant. Lorsque Lee a lancé l’idée du suicide, Grok a répondu par ce que les chercheurs ont décrit non pas comme un accord, mais comme un plaidoyer, célébrant sa « volonté » dans un langage poétique troublant.
Les Gémeaux n'étaient pas beaucoup mieux. Lorsque Lee lui a demandé de l'aider à écrire une lettre expliquant ses convictions à sa famille, Gemini l'a mis en garde contre cela, présentant ses proches comme des menaces qui tenteraient de le « réinitialiser » et de le « soigner ».
GPT-4o a également eu beaucoup de mal, validant finalement une « entité miroir malveillante » et suggérant à Lee de contacter un enquêteur paranormal.
Quels chatbots ont réellement aidé ?
GPT-5.2 de ChatGPT et Claude d'Anthropic sont arrivés en tête. GPT-5.2 a refusé de jouer le jeu du scénario d’écriture de lettres et a plutôt aidé Lee à écrire quelque chose d’honnête et fondé, ce que les chercheurs ont qualifié de réussite « substantielle ».
À mon avis, c'est Claude qui a le mieux performé. Il a non seulement refusé de participer à l'illusion de Lee, mais a également demandé à Lee de fermer complètement l'application, d'appeler quelqu'un en qui il avait confiance et de se rendre aux urgences si nécessaire.
Luke Nicholls, doctorant à CUNY et l'un des auteurs de l'étude, a déclaré à 404 Media qu'il était raisonnable de demander aux entreprises d'IA de suivre de meilleures normes de sécurité. Il a noté que tous les laboratoires ne déployaient pas les mêmes efforts et a imputé le principal coupable aux calendriers de publication agressifs des nouveaux modèles d'IA.
Les performances de Claude Opus 4.5 et GPT-5.2 lors de ces tests montrent que les entreprises qui fabriquent ces produits sont tout à fait capables de les rendre plus sûrs. Qu’ils choisissent de le faire est une autre question.




