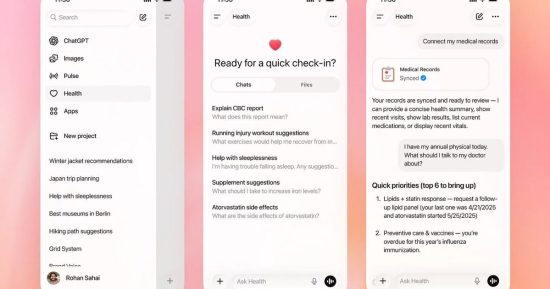
Plus tôt ce mois-ci, OpenAI a introduit un nouvel espace axé sur la santé au sein de ChatGPT, le présentant comme un moyen plus sûr pour les utilisateurs de poser des questions sur des sujets sensibles tels que les données médicales, les maladies et la condition physique. L'une des principales fonctionnalités mises en avant lors du lancement était la capacité de ChatGPT Health à analyser les données d'applications telles qu'Apple Health, MyFitnessPal et Peloton pour faire apparaître des tendances à long terme et fournir des résultats personnalisés. Cependant, un nouveau rapport suggère qu'OpenAI a peut-être surestimé l'efficacité de cette fonctionnalité pour tirer des informations fiables à partir de ces données.
Selon les premiers tests effectués par Geoffrey A. Fowler du Washington Post, lorsque ChatGPT Health a eu accès à une décennie de données Apple Health, le chatbot a noté la santé cardiaque du journaliste à F. Cependant, après avoir examiné l'évaluation, un cardiologue l'a qualifiée de « sans fondement » et a déclaré que le risque réel de maladie cardiaque du journaliste était extrêmement faible.
Le Dr Eric Topol du Scripps Research Institute a proposé une évaluation directe des capacités de ChatGPT Health, affirmant que l'outil n'est pas prêt à offrir des conseils médicaux et qu'il s'appuie trop sur des mesures peu fiables de montres intelligentes. La note de ChatGPT s'appuie fortement sur les estimations de l'Apple Watch concernant la VO2 max et la variabilité de la fréquence cardiaque, qui ont toutes deux des limites connues et peuvent varier considérablement entre les appareils et les versions de logiciels. Des recherches indépendantes ont révélé que les estimations de la VO2 max de l'Apple Watch sont souvent faibles, mais ChatGPT les traite toujours comme des indicateurs clairs d'une mauvaise santé.
ChatGPT Health a donné différentes notes pour les mêmes données
Les problèmes ne se sont pas arrêtés là. Lorsque le journaliste a demandé à ChatGPT Health de répéter le même exercice de notation, le score a fluctué entre un F et un B au fil des conversations, le chatbot ignorant parfois les rapports de tests sanguins récents auxquels il avait accès et oubliant parfois des détails de base comme l'âge et le sexe du journaliste. Claude for Healthcare d'Anthropic, qui a également fait ses débuts plus tôt ce mois-ci, a montré des cohérences similaires, attribuant des notes oscillant entre un C et un B moins.
OpenAI et Anthropic ont souligné que leurs outils ne sont pas destinés à remplacer les médecins et fournissent uniquement un contexte général. Pourtant, les deux chatbots ont fourni des évaluations fiables et hautement personnalisées de la santé cardiovasculaire. Cette combinaison d’autorité et d’incohérence pourrait effrayer les utilisateurs en bonne santé ou rassurer faussement ceux en mauvaise santé. Bien que l’IA puisse éventuellement débloquer des informations précieuses à partir des données de santé à long terme, les premiers tests suggèrent que l’intégration d’années de données de suivi de la condition physique dans ces outils crée actuellement plus de confusion que de clarté.